Open the middle drawer
Qing Lian1, Kent Yu1,2,3, and Lei Zhang1,2,3
1Futian Laboratory
2International Digital Economy Academy (IDEA)
3Visincept
Contact: lianqing1997@gmail.com
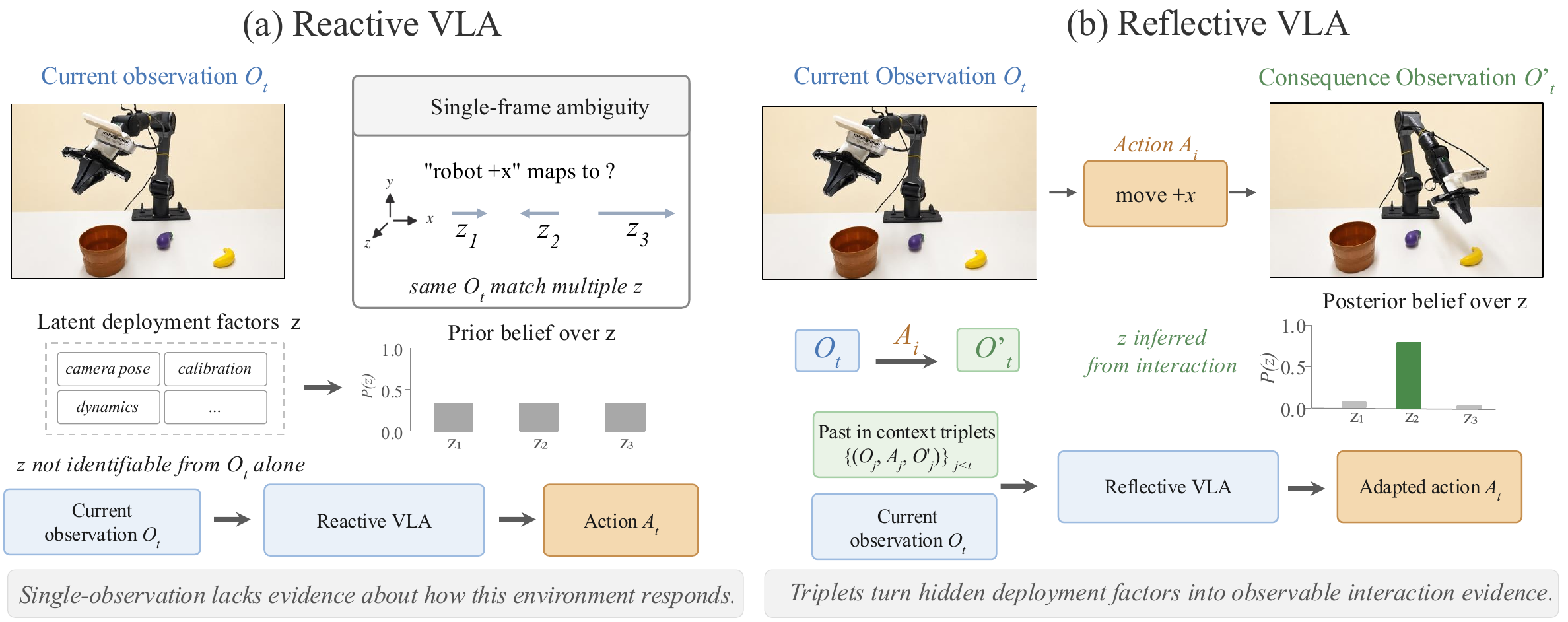
Most vision-language-action (VLA) models are reactive: they predict the next action from the current instruction and observation, implicitly assuming that the current observation fully specifies the action-relevant state. In embodied control, embodiment-specific factors such as camera-to-robot geometry, robot calibration, or systematic actuation bias are often hard to identify from a single observation. We propose Reflective VLA, which conditions each decision on a context of observation-action-consequence triplets. Each triplet records not only what the robot observed and executed, but also how the scene changed afterward, exposing the deployment-specific mapping from actions to observed effects. Across LIBERO, SimplerEnv-Bridge, LIBERO-Plus, LIBERO-Plus-Hard, and real-world cross-camera deployment, Reflective VLA improves generalization while preserving strong in-distribution performance.
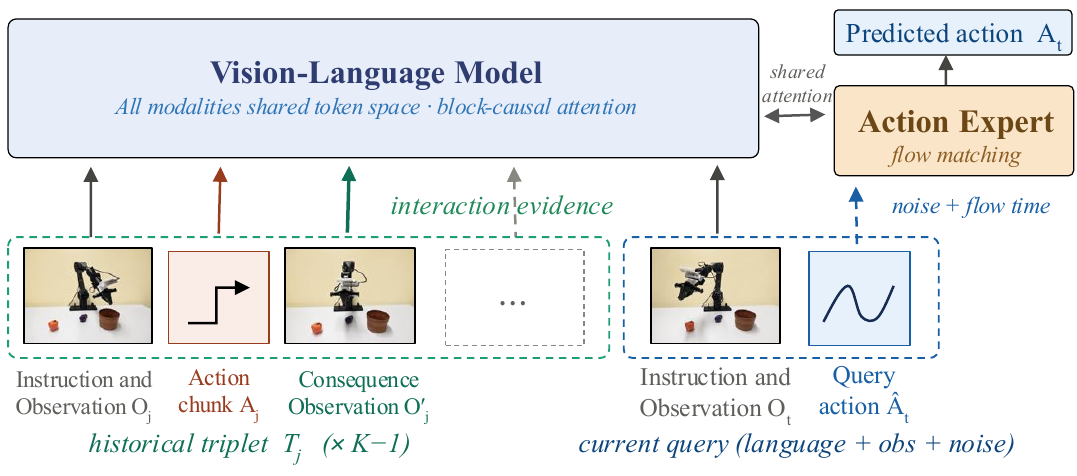
Reflective VLA packs historical triplets (O, A, O') and the current observation into one multimodal prompt. The action expert attends to the full shared VLM token sequence and predicts the next continuous action chunk.
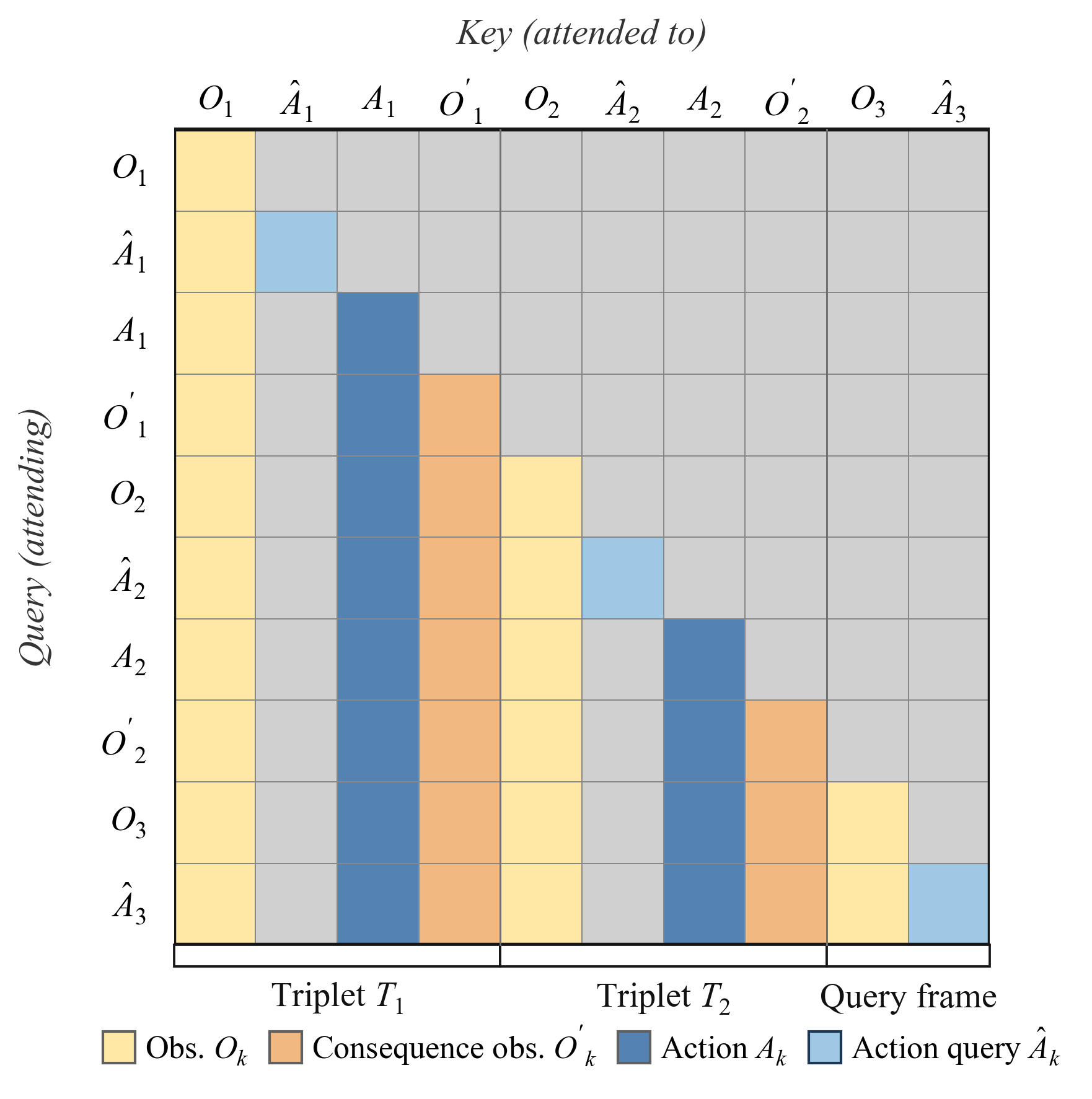
The block-causal mask supervises all sampled targets in one forward pass while preventing future leakage.
Each context unit binds the pre-action observation, executed action chunk, and aligned post-action observation.
A block-causal mask supervises multiple context positions in one forward pass without future leakage.
A rolling context buffer reuses completed triplets and supports real-time online deployment.
| Method | SimplerEnv Avg | LIBERO-Plus Avg | LIBERO-Plus-Hard Avg |
|---|---|---|---|
| Reactive baseline pi_0.5 | 72.9 | 82.3 | 64.6 |
| Reflective VLA (ours) | 78.2 | 87.7 | 68.8 |
| Gain | +5.3 | +5.4 | +4.2 |
Success rates are reported in percent. Reflective VLA preserves nominal benchmark performance and improves robustness under deployment shifts that change sensing or embodiment-specific factors.
| Method | Spatial | Object | Goal | Long |
|---|---|---|---|---|
| Reactive baseline pi_0.5 | 97.5 | 98.2 | 97.8 | 94.0 |
| Reflective VLA (ours) | 98.4 | 99.0 | 98.2 | 94.6 |
| Gain | +0.9 | +0.8 | +0.4 | +0.6 |
| Method | Camera | Robot | Lang | Light | Bg | Noise | Layout | Camera* | Rob. Calib* |
|---|---|---|---|---|---|---|---|---|---|
| Reactive baseline pi_0.5 | 90.0 | 50.0 | 92.9 | 92.0 | 85.8 | 90.2 | 75.0 | 74.0 | 55.2 |
| Reflective VLA (ours) | 95.7 | 72.9 | 92.2 | 92.1 | 92.7 | 95.4 | 73.0 | 76.3 | 61.3 |
Camera* and Rob. Calib* denote the two harder LIBERO-Plus-Hard shifts.
Representative Reflective VLA successful rollouts from LIBERO-Plus-Hard camera perturbation evaluation.
Open the middle drawer
Place the yellow dairy product in the basket
Move the black bowl onto the plate
Turn on the stove and place the moka pot
Real-world robot clips are shown as a four-at-a-time autoplay carousel.