|
I am currently a researcher at IDEA, working on embodied intelligence. Previously, I worked on self-driving cars at DJI Automotive. I received my Ph.D degree from HKUST StatML Group at The Hong Kong University of Science and Technology supervised by Prof. Tong Zhang. Prior to this, I received my Bachelor degree from the University of Electronic Science and Technology of China. My research interests in Physical AI and their application on autonomous driving and robotics.
|

|
|
|
|
|
Jinghang Li, Qing Lian (Project Lead), Yuhan Xi, Qing Jiang Open-source Project, 2026 A general-purpose agent that pairs a VLM planner and verifier with any VLA backend, turning short-horizon skills into long-horizon robot missions via MCP. Project Page/ Code |
|
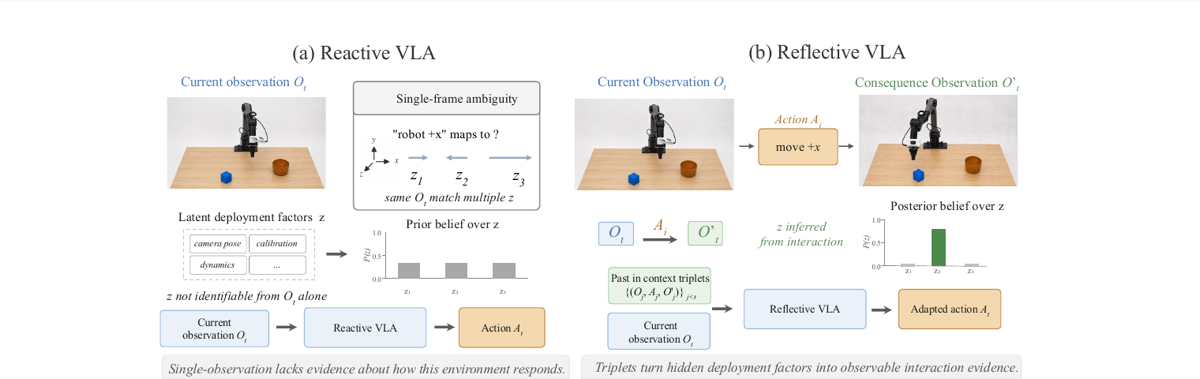
Qing Lian, Kent Yu, Lei Zhang Preprint, 2026 |
|
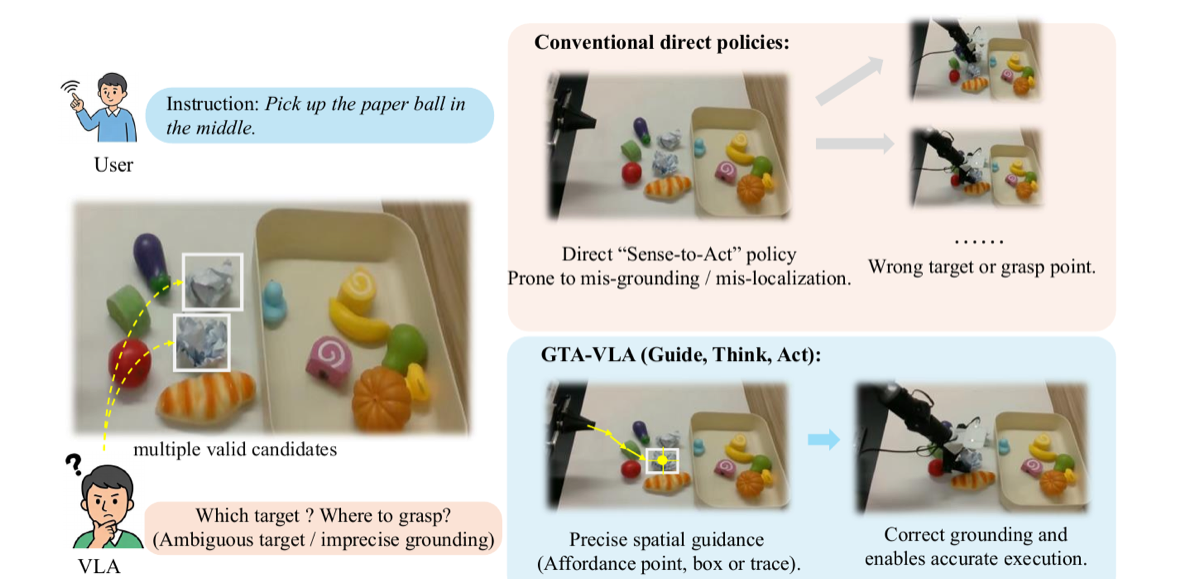
Yiran Ling*, Qing Lian*, Jinghang Li, Qing Jiang, Tianming Zhang, Xiaoke Jiang, Chuanxiu Liu, Jie Liu, Lei Zhang ECCV, 2026 PDF/ Project Page |
|
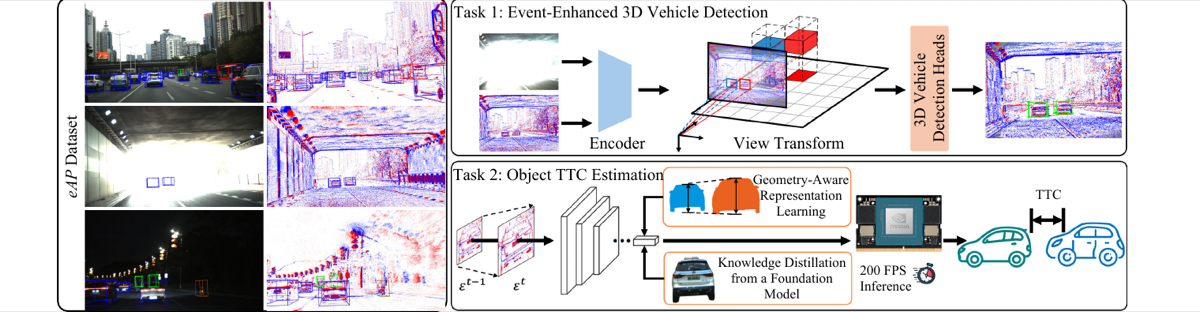
Jinghang Li*, Shichao Li*, Qing Lian, Peiliang Li, Xiaozhi Chen, Yi Zhou T-RO, 2026 PDF/ Project Page |
|
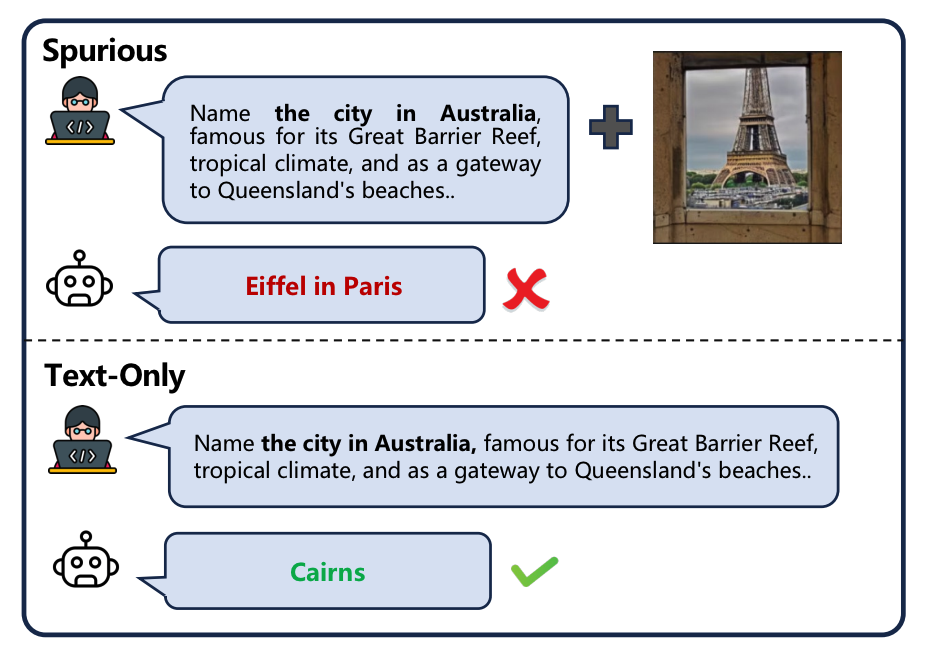
Tianyang Han*, Qing Lian*, Rui Pan, Renjie Pi, Jipeng Zhang, Shizhe Diao, Yong Lin, Tong Zhang EMNLP ,2024 |

|
Renjie Pi, Tianyang Han, Jianshu Zhang, Yueqi XIE, Rui Pan, Qing Lian, Hanze Dong, Jipeng Zhang, Tong Zhang EMNLP ,2024 |
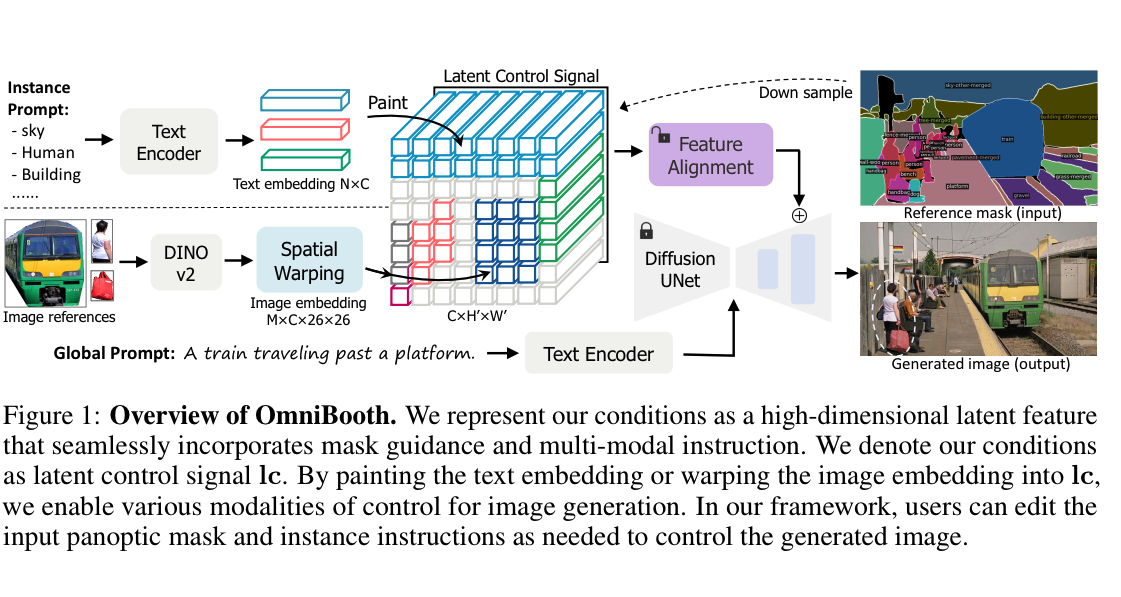
|
Leheng Li, Weichao Qiu, Yingjie Cai, Xu Yan, Qing Lian, Bingbing Liu, Ying-Cong Chen; Arxiv preprint 2410.04932 ,2024 |
|
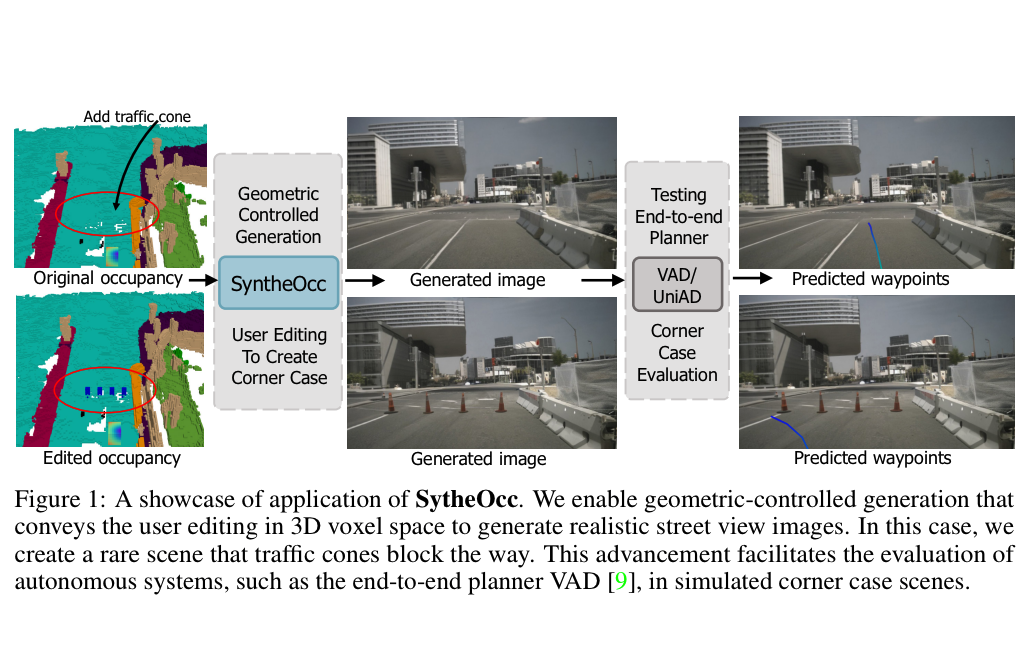
Leheng Li, Weichao Qiu, Yingjie Cai, Xu Yan, Qing Lian, Bingbing Liu, Ying-Cong Chen Arxiv preprint 2410.04932 ,2024 |
|
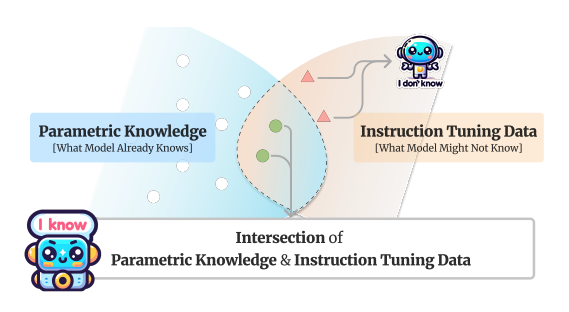
Hanning Zhang, Shizhe Diao, Yong Lin, Yi Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, Tong Zhang NAACL Outstanding paper,2024 |
|
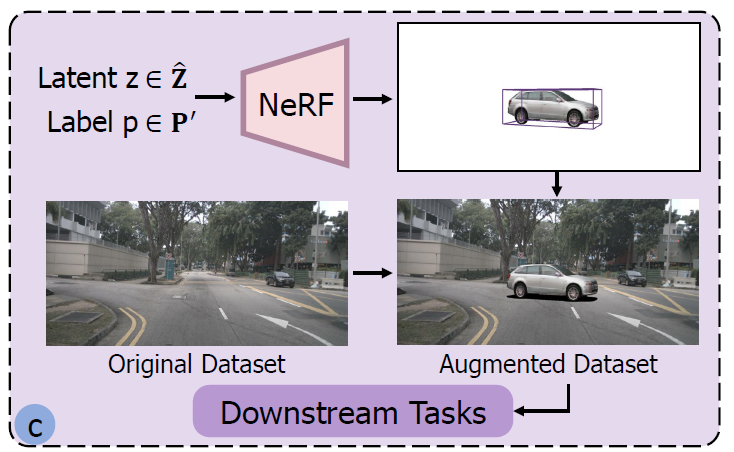
Leheng Li, Qing Lian, Yingcong Chen IROS,2024 |
|
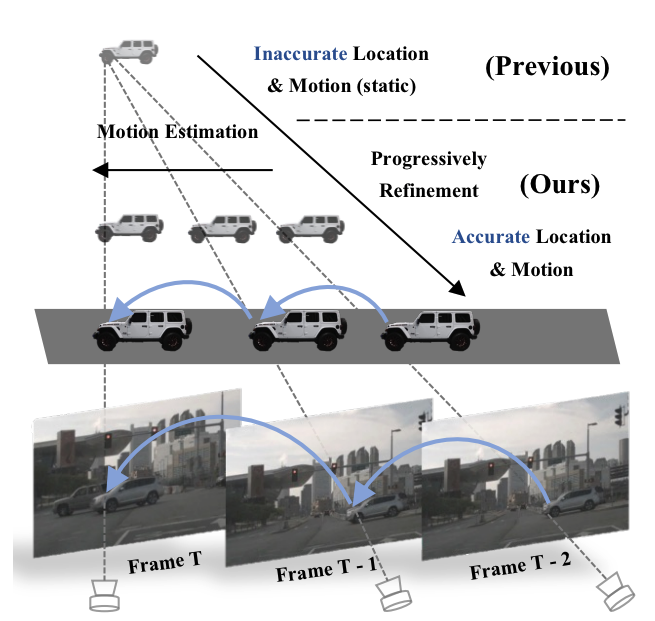
Helbert PAAT, Qing Lian, Weilong Yao, Tong Zhang ICRA,2024 |
|
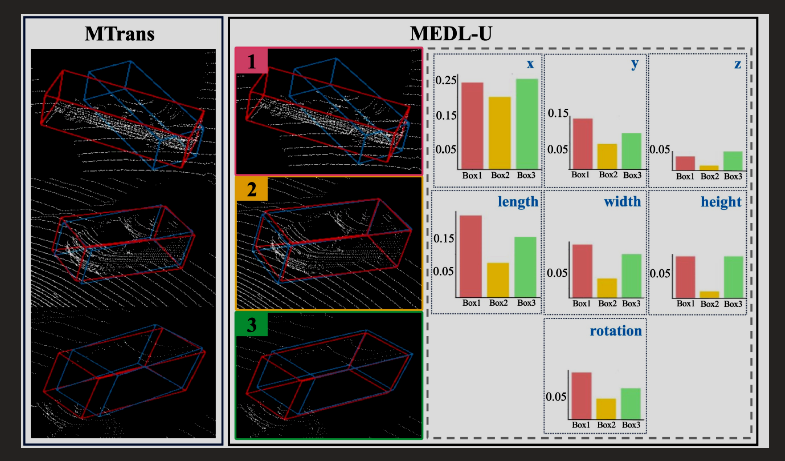
Qing Lian, Tai Wang, Weilong Yao, Dahua Lin, Jiangmiao Pang CoRL,2024 |
|
Leheng Li, Qing Lian Luozhou Wang, Ningning Ma, Ying-Cong Chen, CVPR ,2023 PDF/ Code |
|
Tai Wang*, Qing Lian* Chenming Zhu, Xinge Zhu, Wenwei Zhang Arxiv , 2021 abs.2207.12716 (Waymo Camera-only Challenge solution 2nd place report.) PDF/ Code |
|
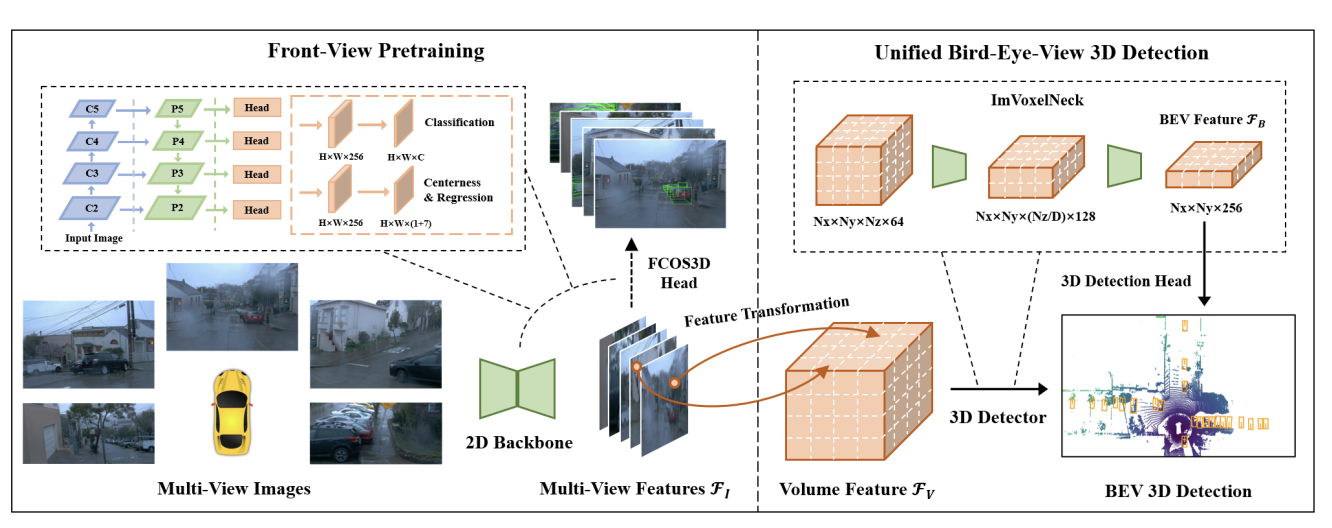
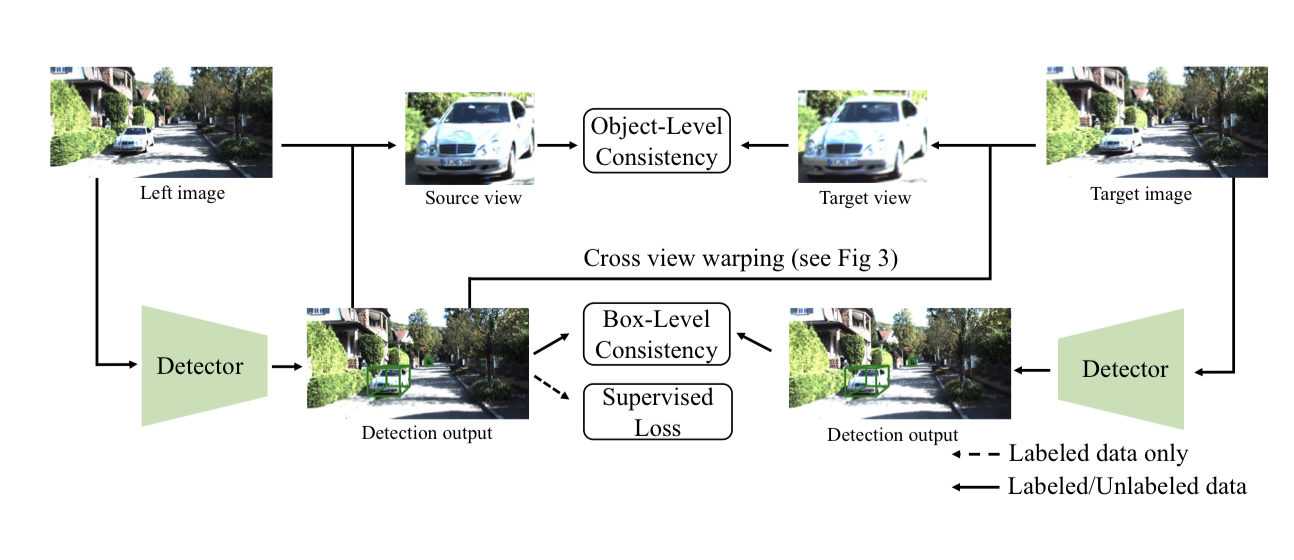
Qing Lian, Yanbo Xu, Weilong Yao, Yingcong Chen, Tong Zhang ECCV, 2022 PDF/ Code |

|
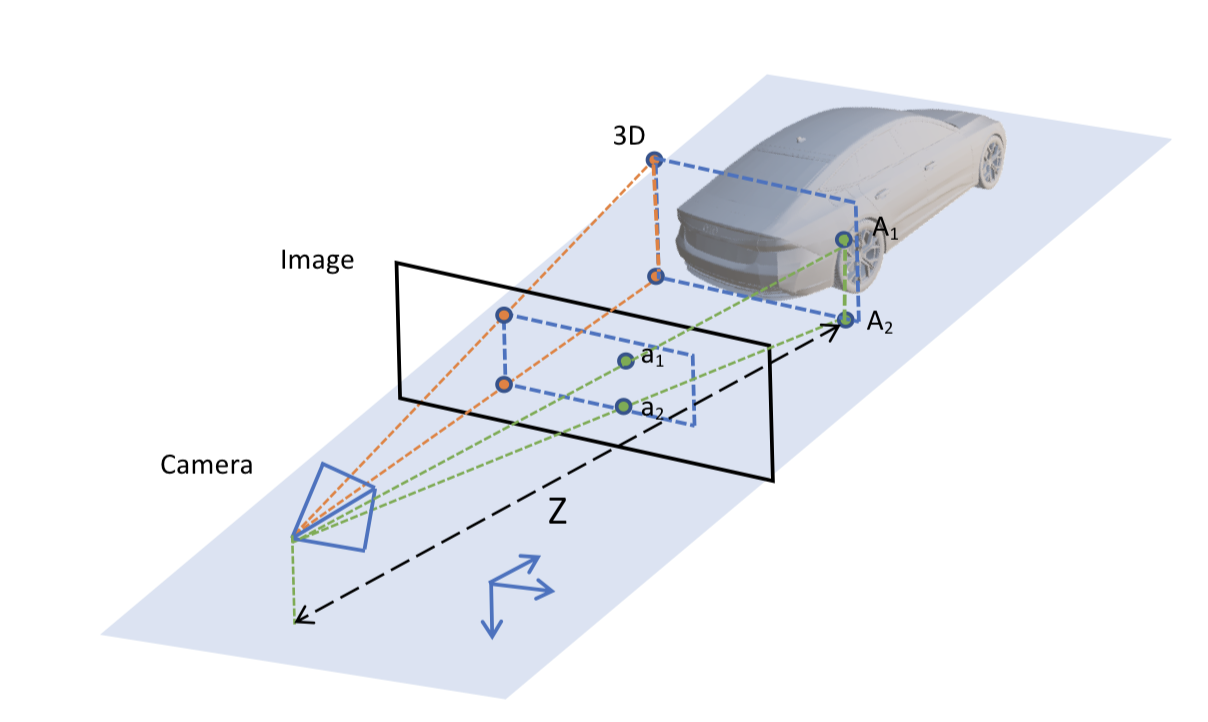
Qing Lian, Peiliang Li, Xiaozhi Chen CVPR, 2022 |
|
Qing Lian Botao Ye, Ruijia Xu, Weilong Yao, Tong Zhang CVPR, 2022 arXiv |

|
Yong Lin, Qing Lian, Tong Zhang ICML workshop on UDL (Uncertainty & Robustness in Deep Learning), 2021 PDF/ Code |

|
Xinwei Shen, Furui Liu, Hanze Dong, Qing Lian, Zhitang Chen, Tong Zhang JMLR 2021 PDF/ Code |
|
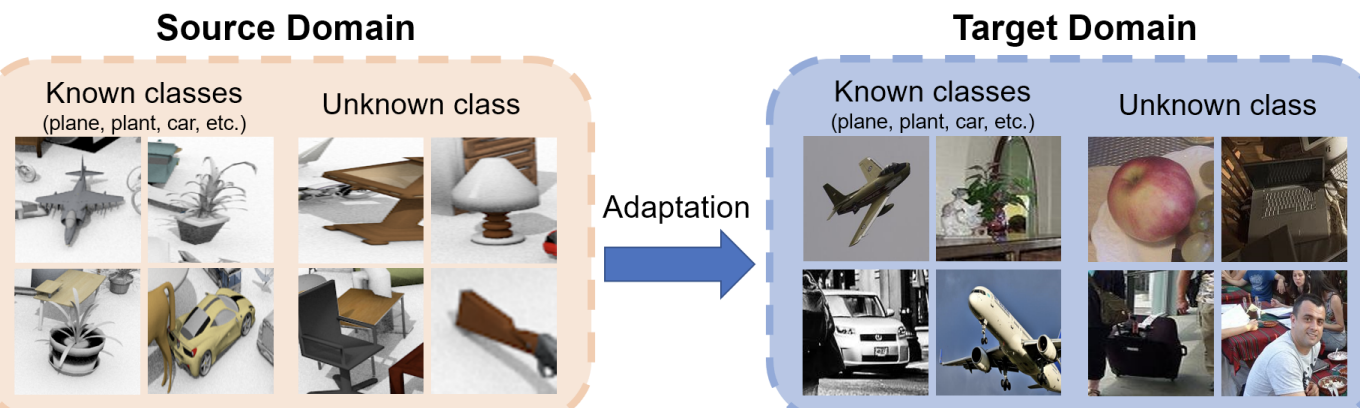
Qing Lian, Wen Li, Lin Chen, Lixin Duan Arxiv 2019 PDF/ Code |
|
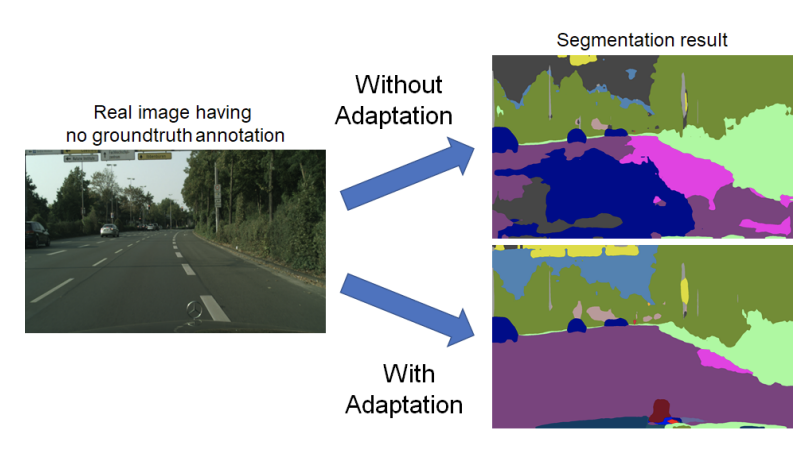
Qing Lian, Fengmao Lv, Lixin Duan, Boqing Gong ICCV 2019 PDF/ Code |
|
|
|
May. 2021 - Nov. 2021, DJI Automative; |
|
Dec. 2018 - May. 2019, Tencent AI Lab; |
|
Feb. 2018 - Sep. 2018, SenseTime; |
|
Oct 2017 - June. 2019, Diggers group at UESTC; |
|
|
| CVPR Wad Detection Domain Adaptation Challenge(Rank 2nd), 2019 |
| ECCV VisDA Challenge(Rank 2nd), 2018 |
| CVPR Webvision Challenge(Rank 2nd), 2018 |
|
This website is based on Jon Barron's template (source code) |